Note
Go to the end to download the full example code.
Analyzing Demand Convergence#
In this example we show how to use analyze demand convergence for across model iterations
Imports#
from pathlib import Path
import numpy as np
from polaris.analyze.trip_metrics import TripMetrics
from tqdm import tqdm
Data Sources#
Open the demand database for analysis
model_fldr = Path("/tmp/Bloomington")
supply_db = model_fldr / "Bloomington-Supply.sqlite"
demand_file = "Bloomington-Demand.sqlite"
iterations = 4
demand_files = {f"iter_{i}": model_fldr / f"Bloomington_iteration_{i}" / demand_file for i in range(1, iterations + 1)}
Data retrieval#
data = {}
for k, file_name in tqdm(demand_files.items()):
tm = TripMetrics(supply_file=supply_db, demand_file=file_name)
data[k] = tm.data
0%| | 0/4 [00:00<?, ?it/s]
25%|██▌ | 1/4 [00:00<00:01, 2.42it/s]
50%|█████ | 2/4 [00:00<00:00, 2.20it/s]
75%|███████▌ | 3/4 [00:01<00:00, 2.86it/s]
100%|██████████| 4/4 [00:01<00:00, 3.29it/s]
100%|██████████| 4/4 [00:01<00:00, 2.95it/s]
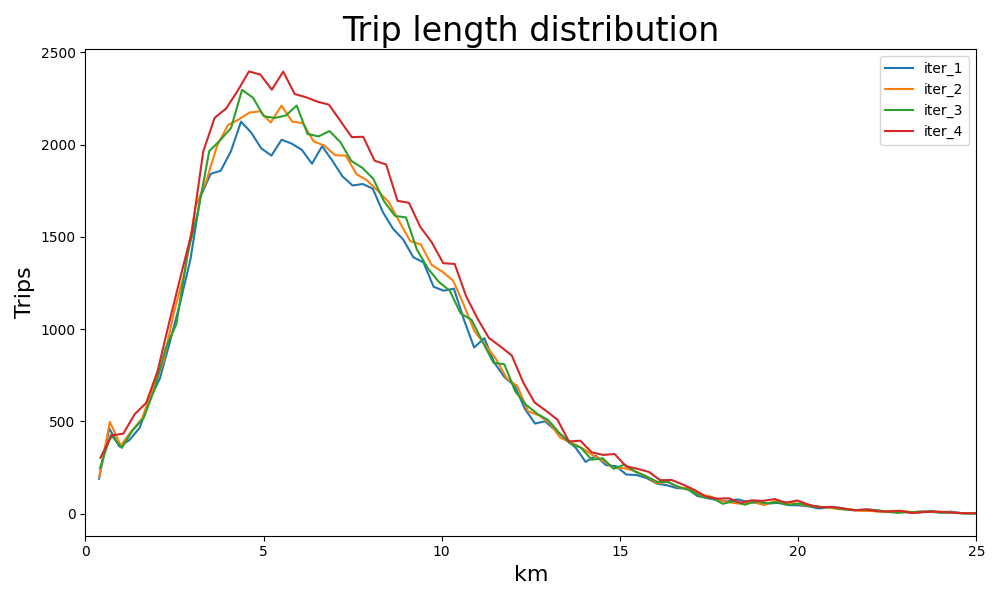
Plotting Trip Length distribution#
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 6))
for k, df in data.items():
dfa = df[df.travel_distance > 0]
# For large models, using 200 to 400 bins yields much better curves
y, x = np.histogram(dfa.travel_distance.values / 1000, bins=90)
ax.plot(x[1:], y, label=k)
ax.legend(loc="upper right")
plt.title("Trip length distribution", fontsize=24)
plt.xlabel("km", fontsize=16)
plt.ylabel("Trips", fontsize=16)
plt.xlim(0, 25)
plt.tight_layout()
# fig.savefig("D:/my_project/TLFD.png")
plt.show()
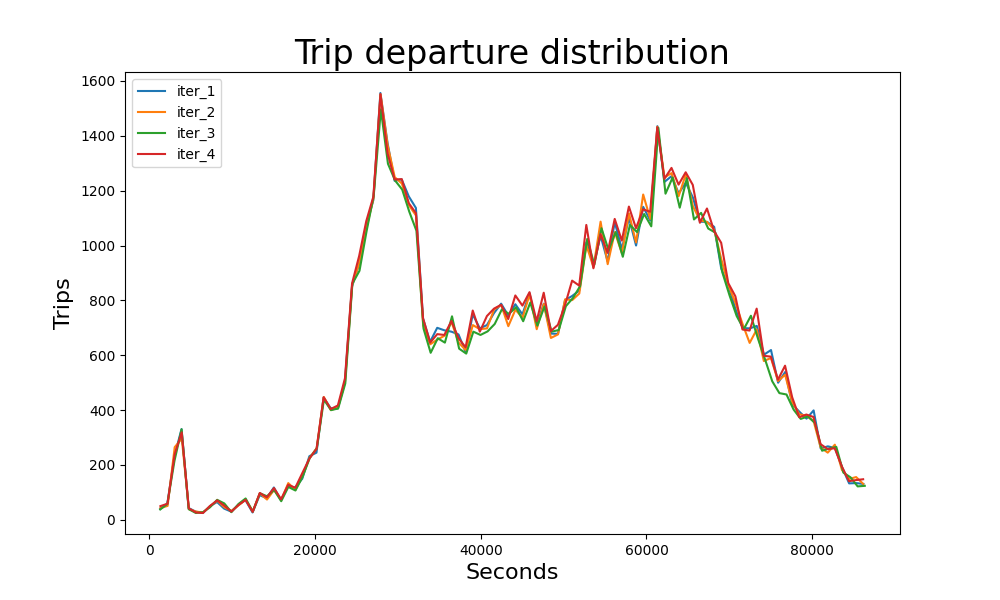
Plotting travel departure distribution#
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 6))
for k, df in data.items():
y, x = np.histogram(df.tstart.values, bins=100)
ax.plot(x[1:], y, label=k)
ax.legend(loc="upper left")
plt.title("Trip departure distribution", fontsize=24)
plt.xlabel("Seconds", fontsize=16)
plt.ylabel("Trips", fontsize=16)
plt.show()
Plotting correlation for origins and destinations to zones for successive iterations#
def correlate_iterations(df1, df2):
df1a = df1.rename(columns={"origins": "o_a", "destinations": "d_a"})
df2a = df2.rename(columns={"origins": "o_b", "destinations": "d_b"})
df = df1a.join(df2a).fillna(0)
return np.corrcoef(df["o_b"].values, df["o_a"].values)[0, 1], np.corrcoef(df["d_b"].values, df["d_a"].values)[0, 1]
trip_vectors = {}
for i in range(iterations):
df = data[f"iter_{i + 1}"]
df1 = df.groupby(["origin"]).count()[["trip_id"]].rename(columns={"trip_id": "origins"})
df2 = df.groupby(["destination"]).count()[["trip_id"]].rename(columns={"trip_id": "destinations"})
trip_vectors[f"iter_{i + 1}"] = df1.join(df2).fillna(0)
origins = []
destinations = []
for i in range(iterations - 1):
df1 = trip_vectors[f"iter_{i + 1}"]
df2 = trip_vectors[f"iter_{i + 2}"]
o, d = correlate_iterations(df1, df2)
origins.append(o)
destinations.append(d)
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 6))
plt.plot(origins)
plt.plot(destinations)
plt.ylim(0.9, 1.05)
plt.title("Correlation between successive iterations for both origins and destinations", fontsize=16)
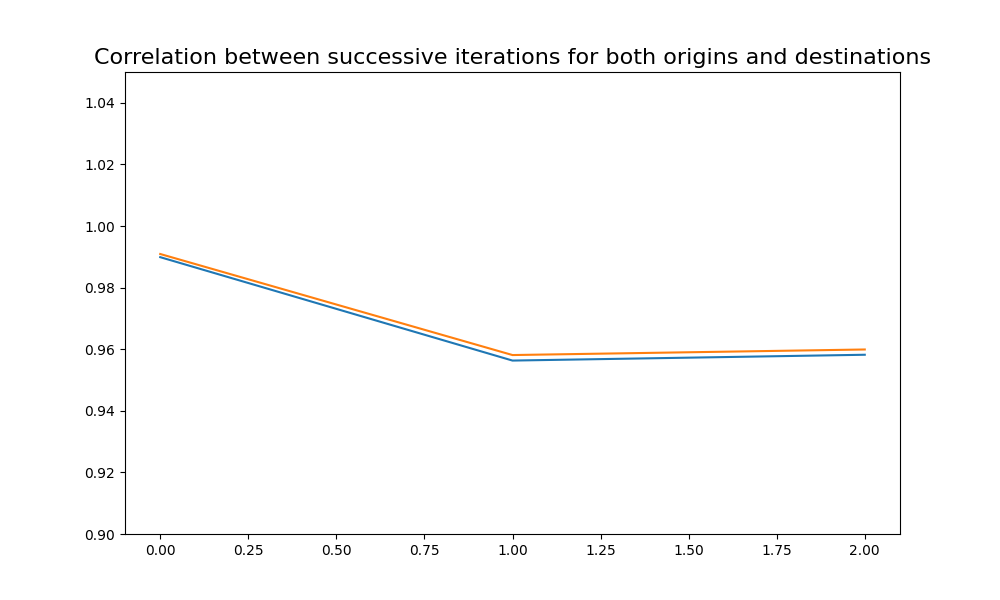
Text(0.5, 1.0, 'Correlation between successive iterations for both origins and destinations')
Total running time of the script: (0 minutes 1.702 seconds)