Note
Go to the end to download the full example code.
Analyzing traffic convergence#
On this example we show how to use analyze traffic convergence for different segments of the results
Imports#
from pathlib import Path
import geopandas as gpd
import matplotlib.pyplot as plt
from polaris.analyze.path_metrics import PathMetrics
from polaris.analyze.result_kpis import ResultKPIs
from polaris.utils.database.data_table_access import DataTableAccess
from polaris.runs.convergence.convergence_iteration import ConvergenceIteration
from polaris.runs.scenario_compression import ScenarioCompression
from polaris.runs.scenario_utils import get_last_iteration
from polaris.utils.testing.temp_model import TempModel
Data Sources#
Open the demand database for analysis
project_dir = TempModel("Bloomington")
iteration_folder = get_last_iteration(project_dir)
supply_db = ScenarioCompression.maybe_extract(Path(iteration_folder) / "Bloomington-Supply.sqlite")
zlayer = DataTableAccess(supply_db).get("Zone").to_crs(4326)
llayer = DataTableAccess(supply_db).get("Link").to_crs(4326)
Data retrieval#
last_iter = ConvergenceIteration.from_dir(iteration_folder)
kpis = ResultKPIs.from_iteration(last_iter)
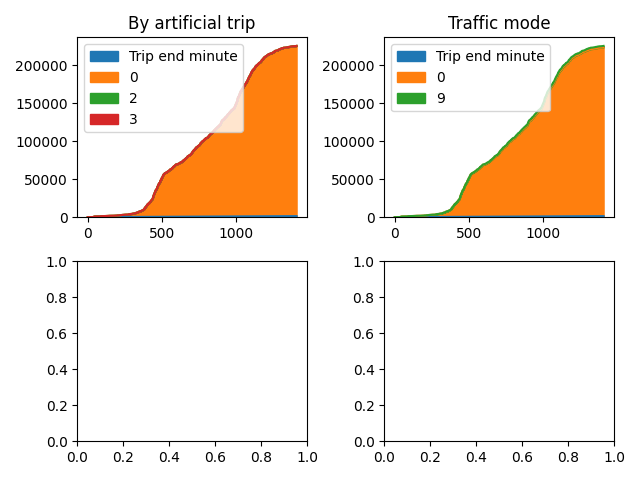
Plotting aggregate results#
def chart_metric(df, metric: str, axis=None):
df.plot.area(ax=axis)
axis.set(title=metric)
df = kpis.metric_traffic_cumulative_gap()
fig, axis = plt.subplots(2, 2)
all_axis = [axis[0, 0], axis[0, 1], axis[1, 0], axis[1, 1]]
for metric, ax in zip(df.metric.unique(), all_axis):
df_ = df[df.metric == metric]
df_ = df_.dropna(axis=1, how="any").sort_values(by="Trip end minute")
chart_metric(df_, metric, ax)
# Combine all the operations and display
plt.tight_layout()
plt.show()
Totals per zone and link#
pm = PathMetrics(demand_file=last_iter.files.demand_db, h5_file=last_iter.files.result_h5)
traces = pm.data
gdf = llayer.sjoin_nearest(zlayer, how="inner")[["link", "zone"]]
gap_per_zone = (
traces.merge(gdf, left_on="link_id", right_on="link").groupby(["zone"]).sum()[["absolute_gap"]].reset_index()
)
plot_zone_layer = zlayer.merge(gap_per_zone, on="zone").drop(columns=["geo"])
gap_per_link = traces.groupby(["link_id"]).sum()[["absolute_gap"]].reset_index()
plot_link_layer = llayer.merge(gap_per_link, left_on="link", right_on="link_id", how="left").drop(columns=["geo"])
map_center = (zlayer.geometry.centroid.x.mean(), zlayer.geometry.centroid.y.mean())
# Fill in any NaN to avoid kepler GL treating it as a string
plot_link_layer.absolute_gap = plot_link_layer.absolute_gap.fillna(0.0)
plot_zone_layer.absolute_gap = plot_zone_layer.absolute_gap.fillna(0.0)
/venv-py312/lib/python3.12/site-packages/geopandas/array.py:411: UserWarning: Geometry is in a geographic CRS. Results from 'sjoin_nearest' are likely incorrect. Use 'GeoSeries.to_crs()' to re-project geometries to a projected CRS before this operation.
warnings.warn(
/home/gitlab-runner/builds/polaris/code/polarislib/docs/examples/result_analysis/plot_convergence_analysis.py:109: UserWarning: Geometry is in a geographic CRS. Results from 'centroid' are likely incorrect. Use 'GeoSeries.to_crs()' to re-project geometries to a projected CRS before this operation.
map_center = (zlayer.geometry.centroid.x.mean(), zlayer.geometry.centroid.y.mean())
Cumulative charts#
import seaborn as sns
import matplotlib.pyplot as plt
cumm_links = gap_per_link.sort_values(by=["absolute_gap"], ascending=False).reset_index(drop=True)
cumm_links = cumm_links.assign(cummulative_relative_gap=cumm_links.absolute_gap.cumsum())
cumm_links.cummulative_relative_gap /= cumm_links.cummulative_relative_gap.max()
sns.lineplot(data=cumm_links["cummulative_relative_gap"])
plt.xlabel("link count")

Text(0.5, 23.633333333333333, 'link count')
Total running time of the script: (0 minutes 2.637 seconds)