Controlling the system#
From a user perspective, the entire process can be controlled from a jupyter notebook (see cluster_control.ipynb). This can be run directly from the VS Code setup on a user’s own machine (with polaris-studio installed locally)
This notebook generally allows users to
Add task to the queue
See the status of the queue and the available workers
See the status of individual tasks
It is generally advisable to have a customized version of this notebook that is relevant to your study and which is version controlled alongside your study specific source code. A good example of this can be found in the GPRA 23 study repository.
Adding a task#
The process of adding tasks to the queue is best described in the example code in the cluster_control.ipynb notebook.
Query list of tasks#
Obtains list of tasks that are queued or running, along with information of what study and scenario it is running, and which worker it is running. The last updated timestamp on the task provides a way to judge if the task is running as expected or not.
from polaris.hpc.eq_utils import task_queue
task_queue(engine)
Querying status of available workers#
Query the status of all available workers linked with EQ/SQL. This query also provides their current status of idle, running a job, or hung with a job for too long.
Stylized rows provides a user-friendly way to parse through several rows of content.
from polaris.hpc.eq_utils import query_workers
query_workers(engine)
Check status of specific task#
>>> from polaris.hpc.eqsql.worker import Worker
>>> task = Task.from_id(engine, 4000)
Task(id=6437, type=python-module, priority=1, status=running, running_on=xover-0043-2070377)
in = | {'run-id': 'base', 'num-threads': 48, 'year': 2020, 'iteration': '19', 'scenario_dir': 'base-seed-2'}
out = | None
>>> task.status
"running"
Killing a running worker#
Very useful if someone goes on holiday and leaves idle nodes on Bebop.
from polaris.hpc.eqsql.worker import Worker
Worker.from_id(engine, worker_id='xover-0036-4095684').terminate(engine)
Killing a running task#
The actual python run by the worker for a task is executed in a background thread so that tasks can be killed remotely through the database. Care should be taken as no user controls are implemented and killing another users tasks is possible - but strongly discouraged.
from polaris.hpc.eqsql.task import Task
Task.from_id(engine, task_id_to_kill).cancel(engine)
Desktop runners#
The advantage of the EQ/SQL approach is that any spare computational capacity can be harnessed together into a whole which is capable of running large simulations across heterogeneous hardware. In general when utilising a desktop machine and adding it into our cluster, we will utilize WSL and run tmux (the terminal multiplexer) to keep our worker loop running in the background and protect against disconnections causing jobs to crash.
For example, when running on VMS-Cxx machines, we will ssh to the machine and then launch WSL and tmux
ssh -l domain\user vms-cxx.es.anl.gov # PowerShell
ssh -l domain\\user vms-cxx.es.anl.gov # Bash
# On first starting the machine, we create a new session and split it up nicely
tmux new-session -s polaris -n BASH -c '~' -d 'tail -f /var/log/supervisor/*' \; split-window -h -d 'htop' \; select-pane -t 1 \; split-window -v -c '~' \;
# On subsequent connections we just attach to the session we started previously
tmux a
TMux Basics#
This will place the user in an environment with three panes as shown in the below figure. In general pane 1 is used for watching the standard output of the runner, pane 2 shows the CPU usage and pane 3 can be used by a user to manipulate the filesystem or watch the progress of a run via other log files.
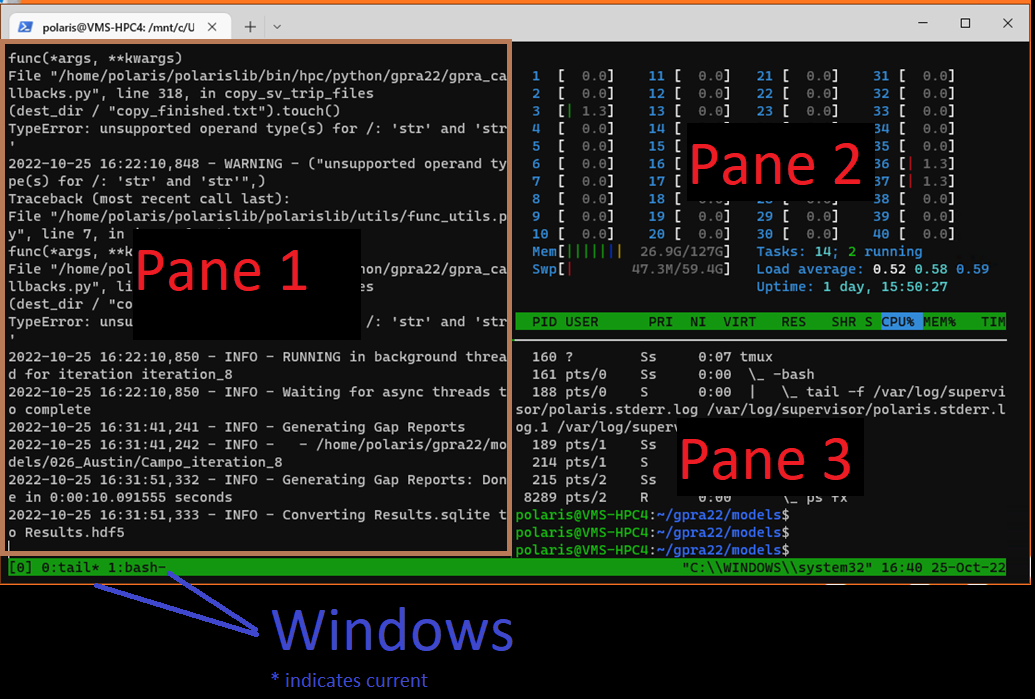
The internet is full of useful resources for mastering tmux but a few basic commands are generally all that are required to use a given session.
Important
Note that all key-combos start with CTRL-b followed by a single character, i.e. the CTRL key should be released after pressing b and before pressing the second part of the combo.
Key Sequence |
Action |
|---|---|
|
Disconnect from the current session |
|
Create a new window |
|
Move to next window |
|
Move to previous window |
|
Cycle to next pane |
|
Reorganise panes |
|
Zoom (or un-zoom) the current pane |
|
Split vertically |
|
Split horizontally |
|
Name the current window |
Launching a second runner#
Often we find ourselves with computers that have capacity to run two POLARIS simulations in parallel. This can be accommodated by launching a second (or third or fourth) worker on a given node. Generally this will be done by creating a second window within the tmux session (named second worker or similar) and then launching the polaris worker_loop script.
cd ~/polarislib.eqsql
./bin/hpc/worker_loop_vms.sh
Additional panes to match the standard are then created by vertical splitting followed by a horizontal split (i.e. CTRL-b % CTRL-b ").
Deploying Runners on Bebop / Crossover#
With standard nodes (as described above) based on a physical machine or desktop, a background service can be started that continually runs tasks for as long as the machine is turned on (and not needed for anything else). However on HPC clusters like Bebop and Crossover jobs are scheduled via an alternate task scheduler to ensure equitable access to the resource. This means that our HPC jobs need to be aware of where they are running and not needlessly consume CPU time waiting for jobs to arrive.
The way this is handled within ANL is that we will expand the number of nodes in our cluster as we have a workload which requires it - for example when a study is being performed. This will be done by scheduling worker nodes to run through slurm (the bebop task scheduler) that will run only for a known period of time and which can be terminated when there is no more work to do.
This process will differ based on the availability of HPC resources for a particular deployment. An example of how this achieved on the Crossover cluster at ANL is provided here for reference.
For information related to setting up the environment to launch workers on Bebop / Improv / Crossover, please check Setting Up Workers
Crossover Case-study#
An estimate of number and capability of required worker nodes is made based on the work-load. For example if we need to run 24 Chicago models:
We know from experience that approximately two Chicago models can be run simultaneously on a single hardware node in this cluster, so we tune our sbatch arguments to allow two slurm jobs to run at once (
--ntasks-per-node=64where there are 128 hyper threads per hardware node).We know that we will likely be able to request 6 hardware nodes without risking the ire of our HPC admins or fellow users so we would schedule 12 workers, each of which we would expect to run 2 of our models (sequentially)
We know that a full-model run will take ~24 hours, so we would estimate that an allocation of 2 * 24 * 1.25 hours would be appropriate (1.25 to allow a 25% buffer for our time estimation)
Once we know how many jobs we need we would schedule that many jobs with the appropriate allocation of time. Each job would be running our wrapper shell script which is customized for that particular cluster (loads required modules, uses anaconda to setup python and requirements.txt, etc.).
for i in {1..12}; do
sbatch --ntasks-per-node=64 --time=2-12:00:00 \
--partition=xxx --account=xxx worker_loop_xover.sh
These worker nodes will then run until they are terminated via sending an EQ_ABORT task or running out of allocated time on the cluster.
As HPC compute is heavily partitioned from the rest of the network - we utilise Globus to transfer data onto and off of the compute nodes. This means that the user who initiates these workers must also have working Globus credentials available on the cluster
Important
Generally it’s enough to authenticate on a login node by running python polaris-studio/utils/copy_utils.py and following the prompts.