Note
Go to the end to download the full example code.
Redistributing fleets based on new control totals#
When the user has data on the expected joint distribution of the fleet across multiple categories, including Vehicle class, power train, ful and its vintage, as well as the distribution of the existing fleet, it is possible to use the Vehicle Redistribution procedure to run an Iterative-Proportional fitting over the original distribution to match targets, including the total fleet for each census tract in the modeled area.
Imports
from os.path import join
import os
from pathlib import Path
from tempfile import gettempdir
import pandas as pd
from polaris.utils.file_utils import get_caller_directory
from polaris.prepare.vehicle_distribution_updater.vehicle_distribution_updater import RedistributeVehicles
Input data
Let’s take a look at the input data
model_path = Path("/tmp/Grid") # We can use any model directory, as that is only used to obtain the vehicle codes
pth = get_caller_directory().parent / "data" / "vehicle_redistribution"
Vehicle file
Note that this file is TAB separated
pd.read_csv(pth / "vehicle_distribution_chicago.txt", delimiter="\t").head()
Target file
pd.read_csv(pth / "target_2040_low.csv").head()
Zone weights
pd.read_csv(pth / "veh_by_zone_chicago.csv").head()
All our files need to be inside the same folder (pth, below)
rv = RedistributeVehicles(
model_dir=model_path,
veh_file=pth / "vehicle_distribution_chicago.txt",
target_file=pth / "target_2040_low.csv",
zone_weights=pth / "veh_by_zone_chicago.csv",
fleet_mode=False,
)
Processing and saving results#
The convergence threshold can be as low as required, as it is nearly guaranteed to converge
rv.process(conv_threshold=0.001, max_iterations=50)
# Two convergence scatter plots are also saved with the outputs for a quick sanity check
rv.save_results(join(gettempdir(), "veh_distr.csv"))
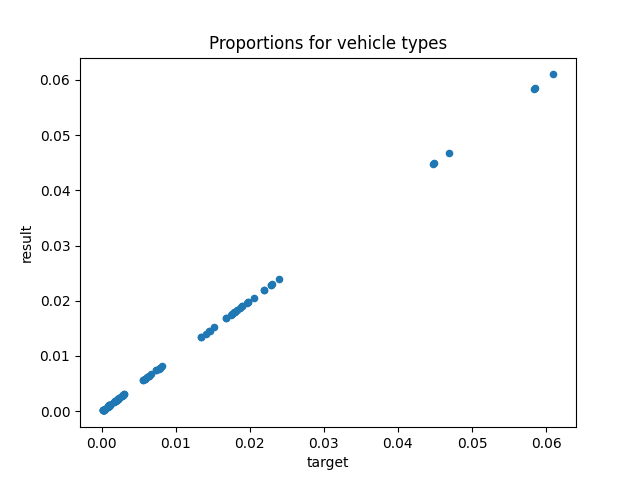
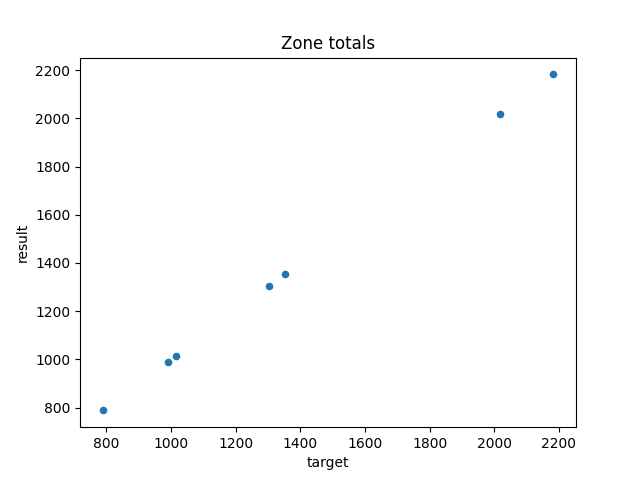
Iteration 1: 0.0s , error 0.1775
Iteration 2: 0.0s , error 0.01309
Iteration 3: 0.0s , error 0.00106
Iteration 4: 0.0s , error 9e-05
Total processing time: 0.2s
Looking at the outputs#
import pandas as pd
df = pd.read_csv(join(gettempdir(), "veh_distr.csv"))
df.head()
Total running time of the script: (0 minutes 0.692 seconds)