Random Choice#
Random choice is at the heart of all simulation modelling and POLARIS is no different. There are two components to making a random choice: The generation of randomness and the probability distribution of the choice process. The randomness part is implemented in RandomEngine, which is a thin wrapper around the std library random engine implementation. To enable reproducible draws, we expose RNG seeding (seed). The underlying generator is chosen to be a linear congruential engine rather than a Mersene Twister as they are significantly faster to instantiate, are much more memory efficient and satisfy all required statistical properties.
To illustrate the intended usage of these classes, let us consider a simple uniform random number generator:
RNG_Components::Implementations::RandomEngine re(1, 1);
The re object is capable of generating random numbers based on both the uniform and normal distributions.
double uniform_draw = re.get_rand();
double std_normal_draw = re.get_normal();
double normal_draw = re.get_normal(2.0, 0.5);
Drawing numbers directly should be avoided however as we also provide convenience methods for performing most common probabilistic choice actions that random numbers are generally used for.
The easiest type of random choice to make is a simple binary one. For example: “does this agent have a bus-pass?”
double bus_pass_holding_rate = 0.45; // 45% chance of having a bus pass
bool has_bus_pass = re.evaluate_probability(bus_pass_holding_rate); // returns true 45% of the time
The second most common type of decision is to choose an element from a set of things.
vector<tMT::zone_type*>& zones = get_zones(); // get some zones to choose from
tMT::zone_type* chosen_zone = re.choose_element(zones); // Choose a zone uniformly
This is a very common operation and has been implemented to be as fast as possible - as we are assuming a uniform probability of all elements, we can calculate the index of the chosen element using constant time index algebra.
However, it’s often required to move away from uniform choice and add some weighting function. For example we may want to choose our zone with a probability based on its population.
In that case we can use two versions of choose_element that take either a weighting function or a standard library discrete_distribution.
// define a weight function that is just the population of the zone
auto get_population = [=](tMT::zone_type* z) { return z->num_people(); };
// choose a zone using that weight function
tMT::zone_type* chosen_zone = re.choose_element(zones, get_population);
We provide two ways to generate the appropriate discrete_distribution object from either our zones and weight function or from pre-existing weights.
// Pre-compute a std::distribution based on the things and a weight function
discrete_distribution<> weight_dist = preprocess_distribution(zones, get_population);
// Or if we already have a set of weights from somewhere else
discrete_distribution<> weight_dist = preprocess_distribution(weights);
// Make choice
tMT::zone_type* chosen_zone = re.choose_element(zones, weight_dist);
These two forms have slightly different performance characteristics and which to use will be based on the type of choices being made and the cost/complexity of the weight function.
The general rule is that if your weight function is simple enough and you are only drawing a small number (i.e. less than 3) of times, you should use the form which takes a weight function.
If you have a complex weight function or are making repeated selections you should take the time to pre-compute the discrete_distribution.
This can be seen in the following charts which show the relative time taken for varying number of draws (k) from a vector of random weights with varying size (n). Values less than 1.0 indicate that the ‘on-the-fly’ version is faster, while >1.0 means that precomputing is faster by the given value (i.e. 2.0 = precomputing takes half the time of ‘on-the-fly’).
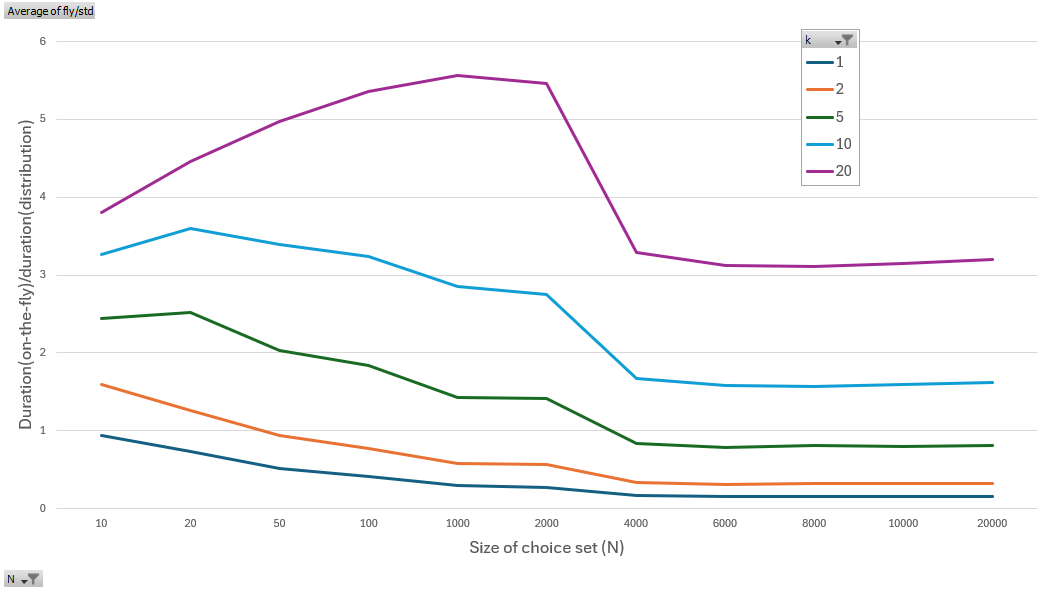
This was calculated using a weight function which was marginally complex w=rand()^4+10000. This is representative of the number of clock cycles required to call a simple getter function on a c++ object.
Important
When using more complex weight functions w=pow(rand(), 1.7) the pre-computed version was always faster.
Normal and Bivariate Normal#
Quite often when defining our models we will want to take advantage of certain common properties of standard distributions. Commonly we will want the cumulative density of the normal distribution up to a given value (area of the lower tail) and while these functions are available as part of the standard (boost::math), we can provide faster implementations if we are willing to give up some accuracy.
Within the Distributions namespace you will find faster versions of the cdf, pdf and icdf functions for Normal and Bivariate Normal distributions. These are reference tested against the corresponding Boost versions for relative performance and accuracy in the following table.
Distribution |
function |
Boost time (us) |
Polaris time (us) |
Relative Accuracy |
|---|---|---|---|---|
Normal |
82201 |
54809 (1.5x) |
1e-8 |
|
cdf |
1263463 |
78035 (16.2x) |
1e-8 |
|
icdf |
384987 |
50369 (7.6x) |
2e-5 |
|
Bivariate Normal |
cdf |
- |
- |
- |
For other distributions such as binomial or poisson, or functions such as the gamma, beta, error and their inverses - the reader is encouraged to use the standard versions where possible and to test the performance if it is in a critical piece of code.
See https://www.boost.org/library/latest/math/ for more details.
Consistent seeding and reproducability#
It is good practice to make stochastic simulations reproducible. For example, running the POLARIS demand model twice with exactly the same inputs should lead to the same demand model outputs. POLARIS implements this by having a separate random number generator per agent and model (e.g., person location choice model, person mode choice model, etc.). These generators are consistently seeded based on agent id and model id. Additionally, all seeds can be reproducibly changed with a scenario parameter such that the influence of stochasticity can be consistently studied.
POLARIS also provides a global random number engine, global_re, however it is only reproducible for single-threaded runs.